 Hepmade
Hepmade  IOT solutions and Systems
IOT solutions and Systems  Automation
Automation  Digital Mobility
Digital Mobility  Sports & Hospitality
Sports & Hospitality
Agentic Multimodal AI in 2025: Architecture, Tools & Use‑Cases
In 2025, Agentic Multimodal AI is set to revolutionize the way systems interpret and act on diverse inputs, by combining perception, reasoning, and autonomous decision-making across text, image, video, and audio modalities to deliver context-aware and human-like responses in real time.The landscape of artificial intelligence is rapidly evolving, with multi-modal agentic applications emerging as one of the most promising developments. These sophisticated systems combine various data types and autonomous decision-making capabilities to create more human-like and effective AI solutions. This article explores the concept, architecture, and implementation of multi-modal agentic applications, along with practical code examples to help you get started.
What Are Multi-Modal AI Agents?
Multi-modal AI agents are comprehensive information processing systems capable of analyzing different types of data inputs-such as text, images, audio, and video-and integrating them into coherent understanding and responses. Unlike traditional AI models that typically process only one data type, multi-modal agents create broader context, increased flexibility, and more effective interactions.
These agents rely on one or more large language models (LLMs) or foundation models to break down complex tasks into manageable sub-tasks. They have access to defined tools, each with descriptions that help the agent determine when and how to use these tools to address challenges.
Key Components of Agentic Multimodal AI 2025:
- Multiple Data Type Processing: Can interpret text, images, audio, and video simultaneously
- Contextual Understanding: Cross-references data across modalities for deeper insights
- Autonomous Decision Making: Selects and uses appropriate tools based on the task
- Human-like Interaction: Creates more natural and intuitive user experiences
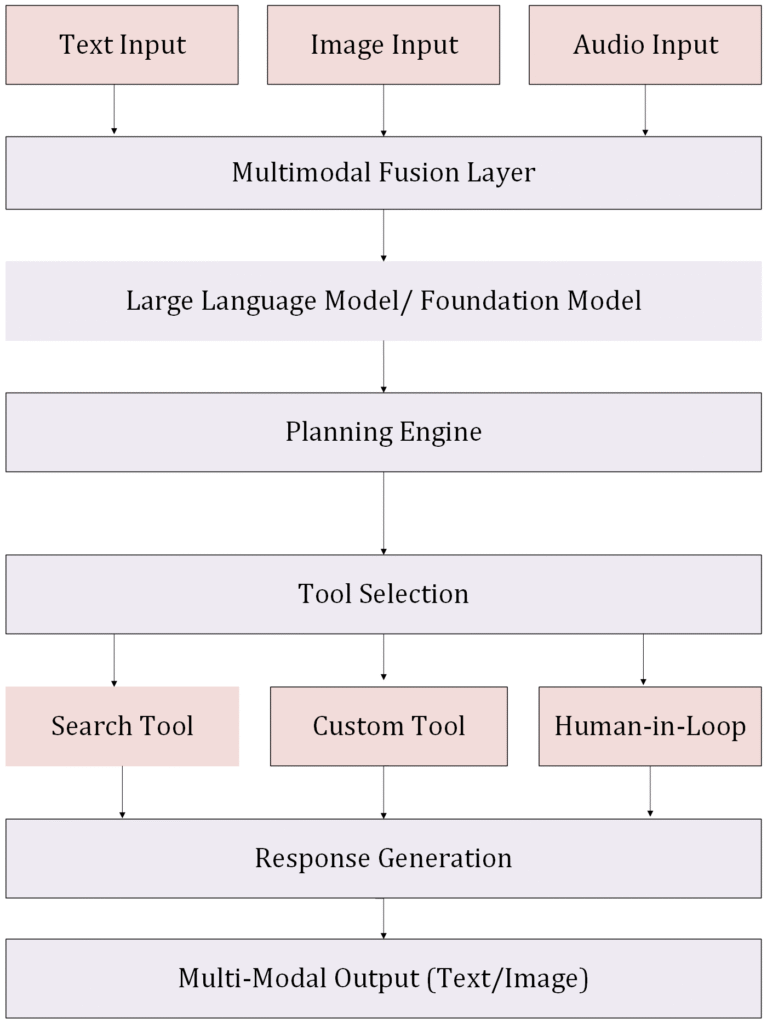
The Architecture of Multi-Modal AI Agents
The development of effective multi-modal AI agents involves integrating technologies that can handle distinct types of data inputs and processing. The core architectural components include:
Multimodal Fusion Techniques
At the heart of multi-modal AI is the ability to merge information from different sources into a coherent representation. Three main fusion techniques are commonly employed:
- Early Fusion: Combines raw data inputs at the initial stage before processing, allowing for rich joint feature extraction but requiring more computational resources
- Late Fusion: Processes each modality independently and merges the results at the decision-making stage, offering modularity but potentially missing deeper cross-modal interactions
- Hybrid Fusion: Combines aspects of both early and late fusion for optimized performance
Tool Integration
Multi-modal agents can access various tools to accomplish tasks, including:
- Search engines and research portals
- APIs for specific services
- Human-in-the-loop capabilities for uncertain scenarios
- Specialized functions for specific operations
Block Diagram: Agentic Multimodal AI Architecture
Implementing Agentic Multimodal AI
Several platforms facilitate the development of Agentic Multimodal AI. According to recent research, the top platforms for building these agents in 2025 include LangChain, Microsoft AutoGen, LangGraph, Phidata, Relevance AI, CrewAI, and Bizway.
Practical Implementation with LangChain
Let’s look at how to implement a basic multi-modal agent using LangChain. The example below demonstrates how to pass multimodal data (image and text) to a model:
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
import base64
import httpx
# Set up OpenAI API key
import os
os.environ['OPENAI_API_KEY'] = "your-api-key-here"
# Initialize the model
model = ChatOpenAI(model="gpt-4o-mini")
# Image URL
image_url = "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg"
# Fetch and encode the image
image_data = base64.b64encode(httpx.get(image_url).content).decode("utf-8")
# Create a message with both text and image
message = HumanMessage(
content=[
{"type": "text", "text": "describe the weather in this image"},
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{image_data}"},
},
],
)
# Get the response
response = model.invoke([message])
# Print the result
print(response.content)
This code demonstrates how to pass both text and image data to a multimodal model and receive a response describing the weather shown in the image.
Creating Custom Tools for AI Agents
Multi-modal agents become powerful when they can utilize specialized tools. Here’s how to create a custom weather tool and bind it to a model:
from typing import Literal
from langchain_core.tools import tool
# Define a custom tool with restricted input options
@tool
def weather_tool(weather: Literal["sunny", "cloudy", "rainy"]) -> None:
"""Describe the weather"""
return f"The weather is {weather}."
# Bind the tool to the model
model_with_tools = model.bind_tools([weather_tool])
# Create a message with text and image
message = HumanMessage(
content=[
{"type": "text", "text": "describe the weather in this image"},
{"type": "image_url", "image_url": {"url": image_url}},
],
)
# Get the response
response = model_with_tools.invoke([message])
# Print tool calls
print(response.tool_calls)
This example shows how to create a custom tool that the model can use to describe weather conditions, with inputs restricted to specific values (“sunny”, “cloudy”, or “rainy”).
Building Complete Agentic Applications
To build a more complete agentic application, we can use LangChain’s agent framework with conversational memory:
from langchain_anthropic import ChatAnthropic
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.messages import HumanMessage
from langgraph.checkpoint.memory import MemorySaver
from langgraph.prebuilt import create_react_agent
# Create the agent components
memory = MemorySaver()
model = ChatAnthropic(model_name="claude-3-sonnet-20240229")
search = TavilySearchResults(max_results=2)
tools = [search]
# Create the agent
agent_executor = create_react_agent(model, tools, checkpointer=memory)
# Use the agent
config = {"configurable": {"thread_id": "abc123"}}
for step in agent_executor.stream(
{"messages": [HumanMessage(content="Tell me about multimodal AI agents")]},
config,
stream_mode="values",
):
step["messages"][-1].pretty_print()
This code creates a more sophisticated agent with search capabilities and conversation memory, allowing for multi-turn interactions.
Applications of Agentic Multimodal AI
Multi-modal AI agents have diverse applications across industries:
- Customer Service: Virtual assistants that can analyze voice tone, text, and images to provide comprehensive support
- Healthcare: Diagnostic tools that can process medical images, patient descriptions, and test results
- Education: Interactive learning systems that respond to various types of student inputs
- E-commerce: Shopping assistants that can analyze product images and text descriptions to provide personalized recommendations
- Content Creation: Tools that can generate or modify content across different modalities
Current Limitations and Safety Considerations
There are three primary limiting factors to AI agents that introduce a certain level of safety:
- The number of loops or iterations the agent is allowed to perform
- The tools available to the agent, which determine its capabilities
- Human-in-the-loop integration, allowing human oversight when the agent’s confidence is below a certain threshold
Conclusion
A Multi-modal AI represent a significant advancement in artificial intelligence, enabling more natural, context-aware, and effective interactions between humans and machines. By integrating multiple data types and employing sophisticated reasoning capabilities, these agents are transforming how we approach complex challenges across industries.
As the technology continues to evolve, platforms like LangChain, Microsoft AutoGen, and others are making it increasingly accessible for developers to create powerful multi-modal agentic applications. Whether you’re looking to enhance customer experiences, streamline operations, or develop innovative new services, multi-modal AI agents offer exciting possibilities for the future of intelligent systems. It’s clear that Agentic Multimodal AI 2025 is not just a trend, but a foundation for next-gen enterprise solutions.
If you’re exploring multimodal agents, add your details here



Don't miss Our Update. Subscribe us for more info.
Request Quote
What type of solution you are seeking?
Please Select One
Your estimated budget
Please Select One